How do you work in research data management?
The world of academic and scientific inquiry is fundamentally changing how it handles its most valuable asset: data. Working in research data management (RDM) is no longer a niche back-office function; it’s becoming an integral component of good scientific practice, ensuring that research findings are trustworthy, reproducible, and accessible long after a grant period ends. [1][4][5] Essentially, RDM is the systemized approach to handling data throughout its entire lifecycle, from the initial idea for a project right through to its final archival or deletion. [6] It requires forethought, careful execution, and a commitment to making data understandable to others, including your future self.
# What RDM Means
At its heart, effective research data management means having a set of organized procedures for collecting, storing, documenting, describing, sharing, and preserving research data. [3][5] This isn't just about where you save your files; it encompasses how you name them, what context you provide for them, where they are backed up, and who can access them and under what conditions. [6] Institutions and funders increasingly mandate these practices, recognizing that poorly managed data can lead to crises in reproducibility or the inability to reuse valuable datasets for secondary analysis. [1][4] For the researcher, adopting RDM shifts data handling from a reactive, last-minute scramble to a proactive, integrated part of the research design. [2]
Many guides outline the lifecycle of data, suggesting key stages that require management attention. While terminology varies slightly, the core concepts remain consistent. For example, one common approach breaks down the process into seven steps, starting with planning and culminating in sharing and preservation. [2] Others structure it around the phases of the research project itself: planning, creation, analysis, and archival. [6] The key takeaway is that management activities must span the entire duration of the data's existence, not just the final moments before publication. [5]
# Data Lifecycle Steps
Understanding the process means recognizing that different actions are required at different times. If we look at a generalized set of required activities, we can map them onto the research timeline.
# Initial Planning
Before a single data point is collected, the foundational work begins with documentation and planning. [2] This stage involves deciding on file formats, storage solutions, and most critically, creating the Data Management Plan (DMP). [3][6] A DMP forces researchers to articulate exactly how they will handle data ethics, privacy, security, and long-term access before the pressure of data collection begins. [5] This upfront investment saves considerable time later.
A practical consideration often overlooked in initial planning is data volume forecasting. If you anticipate collecting, say, 5 terabytes of raw imaging data over three years, you must ensure your institutional storage agreements or personal backup solutions can scale to meet that need and afford the long-term storage costs associated with preservation. Relying on easily accessible but temporary cloud storage for petabytes of data is a common failure scenario that careful RDM planning should avoid. [2]
# Data Collection
As data is generated, the focus shifts to consistency and security. [2] This involves standardizing naming conventions—something that seems small but becomes vital when dealing with thousands of files—and ensuring that data input adheres to protocols established in the DMP. [6] Secure collection often involves immediate, redundant backups, especially if fieldwork or sensitive interviews are involved. [5]
# Processing and Analysis
This middle phase is where the raw data is transformed into findings. RDM here centers on version control and provenance. [3] Which script transformed the raw files into the clean set used for statistics? Which version of the cleaning script yielded the final graph? Maintaining a clear audit trail—knowing who touched what data, when, and why—is paramount for scientific integrity. [6]
# Documentation Details
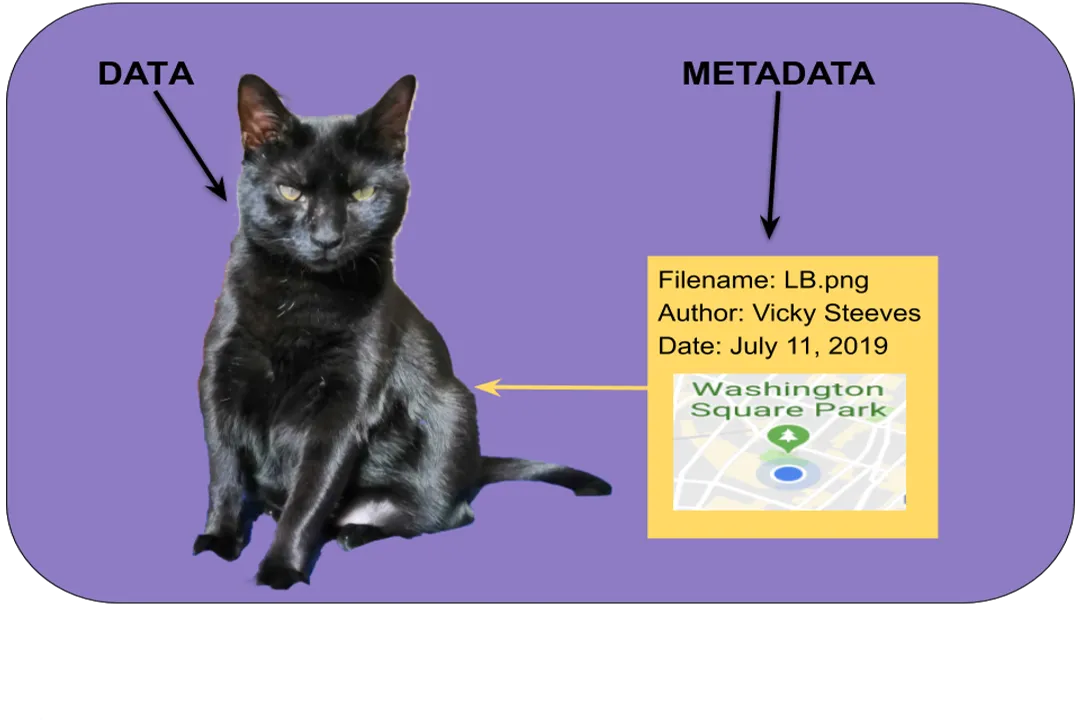
Perhaps the most critical, yet often underappreciated, aspect of RDM is documentation. [8] Data without context is useless noise. Good documentation means creating a metadata record that describes the data object itself, alongside specific documents that describe the process. [8] This includes:
- README Files: Simple text files that live alongside the data, explaining the file structure, variable definitions, software used for analysis, and any data transformations applied. [8]
- Codebooks: Essential for quantitative data, these detail every variable, its format (e.g., integer, string), allowed values, and what those values mean (e.g.,
01=Male,02=Female,99=Missing). [8]
If you are working with a team, establishing a standardized README template early on prevents inconsistencies. For instance, one researcher might list the operating system in the preamble, while another lists the primary analytical software in the codebook appendix. Establishing a single, agreed-upon metadata standard, even a very simple one, prevents this fragmentation. [8]
# Planning Documents
The Data Management Plan (DMP) stands out as the formalized blueprint for RDM. [3] It is often a required component for grant applications or institutional sign-off. [6] A thorough DMP addresses several key areas:
- Data Description: What data will be collected, in what formats (e.g.,
.csv,.tiff,.fastq)? - Standards and Documentation: What naming conventions and metadata standards will be applied?
- Storage and Backup: Where will the data live during the project, and what are the redundancy plans?
- Access, Sharing, and Reuse: Who will have access during the project, and how will the data be made available afterward? This touches on intellectual property rights. [5]
- Preservation: How long will the data be kept, and where will the final version be deposited for long-term access?[6]
Different funding agencies might require slightly different sections or emphasis within their DMP templates, so tailoring the plan to the funder's specific requirements is a necessary administrative step. [3] Yale emphasizes that RDM helps researchers comply with funder mandates, pointing out that these plans are living documents, not static commitments made at the start of the grant. [5]
# Access and Sharing
The desire to share data is a cornerstone of modern open science, but it must be balanced against ethical obligations and privacy concerns. [1] How you manage access during the active research phase often dictates how smoothly sharing can occur later. [5]
# Ethical Constraints
When working with sensitive data—such as human subjects information, protected health information (PHI), or personally identifiable information (PII)—anonymization and de-identification become non-negotiable RDM tasks. [6] The process of stripping identifying markers must be thoroughly documented in the DMP and executed before the data leaves the secure environment for any public repository. [5] In some cases, data cannot be shared publicly due to privacy agreements or institutional review board (IRB) protocols, meaning the preservation focus shifts to providing controlled access or maintaining restricted local access for a set period. [1]
# Repository Selection
Choosing where to deposit data is a key RDM decision. [3] Generalist repositories (like Zenodo or Figshare) are suitable for many data types, but domain-specific repositories (e.g., sequencing data archives, social science data centers) often provide better long-term curation, subject-specific metadata schemas, and community recognition. [6]
When comparing options, consider the persistence of the identifier. A good repository assigns a Digital Object Identifier (DOI) to the dataset, ensuring that the link to your published data will not break, even if the repository renames its internal file structure. [5] This persistence is what makes data citable and reusable. [1]
# Institutional Support
Working in research data management is rarely a solo effort, especially within larger institutions. Researchers often interact with several support structures, highlighting the organizational expertise now dedicated to this area. [9]
For instance, one might first encounter RDM through library services, which often host DMP writing workshops and provide guidance on repository selection and metadata standards. [3][6] Then, the institutional IT department or a dedicated research technology services group might become involved regarding high-performance computing access, long-term archival storage solutions, and data security protocols. [9]
The complexity here is navigating the handoffs. The library might advise on what metadata to collect, while IT manages the secure servers where the raw files reside. An original piece of practical advice for researchers is to identify a single point person within their department or within the central research office who understands both the funder requirements and the institutional storage limitations. This person can act as a translator between the pure science needs and the administrative/technical realities, preventing costly mistakes like using an unapproved local drive for compliance-sensitive data. [9]
Different institutions formalize their offerings in distinct ways. Berkeley, for example, describes its program through service offerings like consultation, policy development, and repository curation. [9] Conversely, others might frame their RDM effort as a set of centralized tools or platforms available to all PIs. [5] Regardless of the structure, the underlying services—consultation, infrastructure, and training—are consistent across the academic landscape. [1]
# Essential Skills for RDM Practice
While specific technical skills vary wildly depending on the discipline—a biologist needs to know GenBank submission protocols, while a social scientist needs to master PII de-identification—a set of core competencies is universal for anyone working in or with RDM.
# Metadata Mastery
As noted, metadata is key. Expertise here means understanding the difference between descriptive, structural, and administrative metadata, and knowing when to apply discipline-specific standards (like Dublin Core for general objects or DDI for surveys) versus using general schema for repository submission. [8] Being able to articulate why a certain set of descriptive tags is necessary for data discovery is a core RDM skill.
# Policy Interpretation
Researchers must understand the policies governing their data. This includes IRB/ethics board requirements regarding informed consent and data retention schedules, as well as specific funder policies (like those from the NIH or NSF) regarding data sharing statements and public access mandates. [1][5] Effective RDM practitioners translate these external legal and administrative requirements into concrete, actionable steps within the research team's daily workflow. [6]
# Data Curation and Quality Assurance
This involves hands-on work to ensure data quality before archiving. This process is often iterative. It may involve running quality checks against expected ranges (e.g., checking that an age variable does not contain values like 250), correcting minor errors identified during the documentation phase, and ensuring that all associated scripts and code run without error on a different machine to confirm reproducibility. [2] A simple quality assurance checklist I’ve found useful involves running three types of checks sequentially:
- Format Check: Do all files match the declared format (e.g., all
.csvfiles open correctly in a standard text editor)? - Completeness Check: Are all expected files present for the main analysis folders?
- Readability Check: Can a colleague unfamiliar with the project successfully execute the primary analysis script using only the provided README and codebook?
If the answer to the third question is no, the data is not yet ready for preservation, regardless of the final publication status. [3]
# Moving Forward
Working in research data management requires adaptability. The tools change, the standards evolve, and funder expectations shift over time. [1] What might have been adequate for an NSF grant five years ago—perhaps storing everything on a local server—is often insufficient for today's requirements which often necessitate public deposition via DOI. [4] The practitioner must remain engaged with updates from organizations like the ACRL or institutional RDM programs to keep pace with these shifts in expectation and technology. [1][9] Ultimately, RDM transforms data from a transient byproduct of research into a lasting scientific asset, deserving of the same rigorous attention as the hypotheses themselves. [4][5]



#Videos
Introduction to Research Data Management - YouTube
Related Questions
#Citations
Keeping Up With… Research Data Management
7 steps to get started with Research Data Management - SciNote ELN
Research Data Management - LibGuides at Duke University
What Is Research Data Management (RDM) for 2026?
Research Data Management
Introduction - Research Data Management Overview
Introduction to Research Data Management - YouTube
Documenting Your Work - Research Data Management
Research Data Management Program